第三章:产品思维与文档驱动
序言:为什么先写文档再写代码?
在让 AI 写代码之前,老师傅按住了你想要狂飙的手。他告诉你,写代码之前,先写文档。如果没有蓝图,AI 很容易就会像脱缰的野马,生成的代码往往缺乏结构,写出一堆谁也看不懂、改不动的功能。
如果你已经有明确的想法,或者只是想做一个小工具、验证一个技术方案,不需要走完整的产品验证流程,可以直接跳到 3.2 与 AI 确认需求 或 3.3 PRD 编写实战。
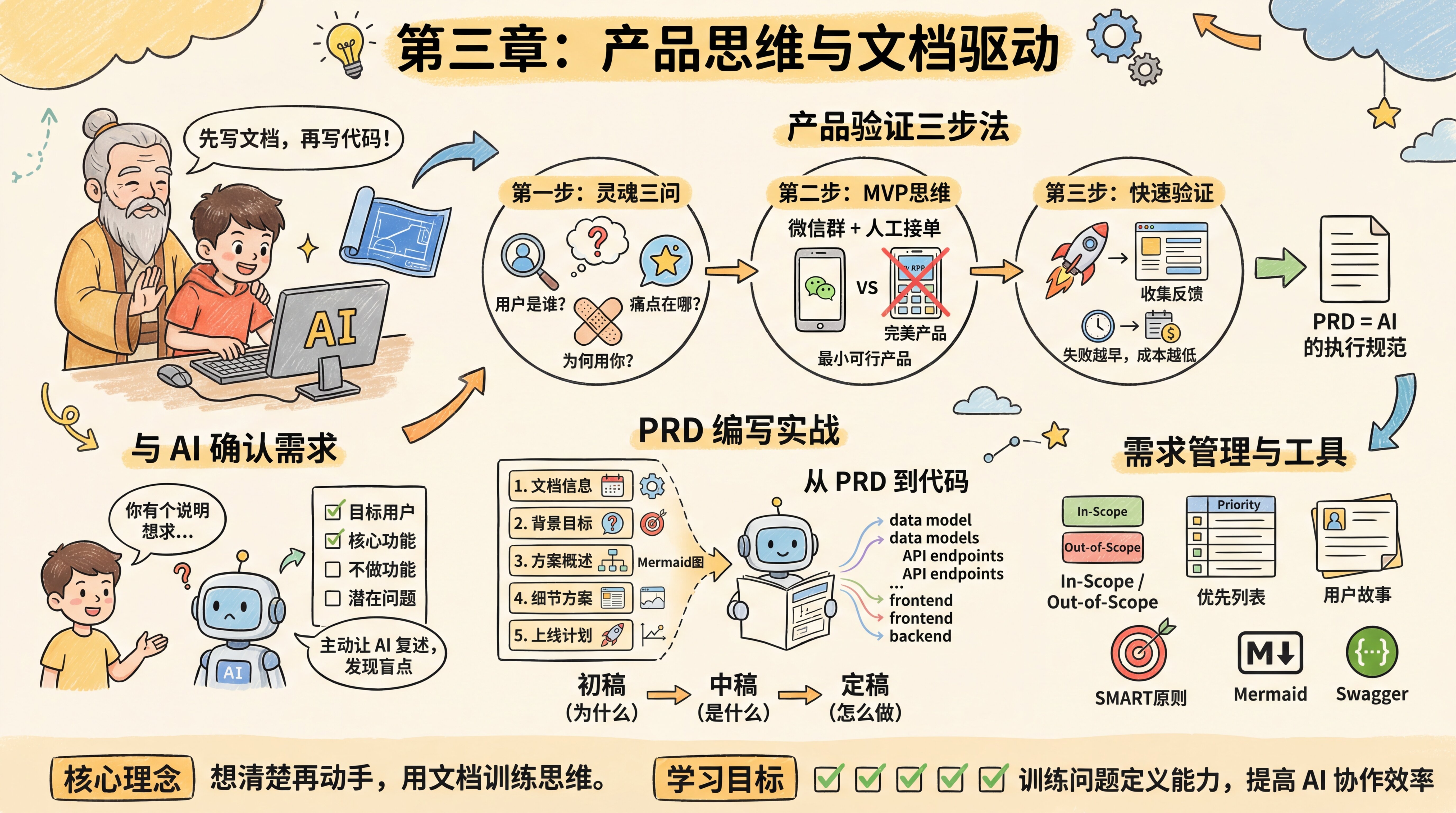
产品验证三步法
老师傅说:"在写任何代码之前,先做产品验证三步法:
第一步:灵魂三问。用户是谁?痛点在哪?为何用你?这三个问题看似简单,但很多人答不上来。如果用户是'所有人',那就等于没有用户。如果痛点是'我觉得需要',那就不是真痛点。如果'为何用你'的答案是'因为我们有最好的技术',那用户根本不在乎。
第二步:MVP思维。能验证假设的最简版本是什么?不要想着一次做出完美产品。先做最小可行产品(MVP),快速验证核心假设。比如要做外卖 App,MVP 可能就是一个微信群 + 人工接单,而不是完整的 App。
第三步:快速验证。用最小成本验证假设。可以先用手工方式服务,或者做一个简单的落地页收集用户反馈。记住:失败得越早,成本越低。
PRD 就是 AI 的执行规范。当你想清楚了上面三步,PRD 就是把这些思考翻译成 AI 能理解的结构化文档。
3.1 想法验证实战 🔴 - 掌握产品验证三步法,避免做没人要的东西
与 AI 确认需求
你发现有时候 AI 的输出五花八门,或者一本正经地胡说八道。更糟糕的是,AI 不会主动提问——当你给出模糊需求时,它会基于训练数据中的常见模式做出假设,然后直接开始生成代码。如果这些假设错了,你将在后续迭代中付出更多沟通成本来纠正。
老师傅告诉你,主动确认的核心是:不要等 AI 来问你,而是让 AI 明确说出它的理解。
每次讨论完需求后,使用确认模板让 AI 复述:目标用户是谁、核心功能有哪些、不做哪些功能、可能有什么问题。这样能在写代码前就发现误解,而不是等到代码跑起来才发现不对。
3.2 与 AI 确认需求 🔴 - 主动让 AI 确认理解,发现盲点
PRD 编写实战
在传统开发中,PRD 是给团队看的;但在 AI 开发中,PRD 更重要的作用是给 AI 提供完整的上下文,让它不需要反复猜测你的意图。
老师傅告诉你,一个完整的 PRD 包含五个核心部分:
第一部分:文档信息。记录文档的当前版本、处于哪个阶段、谁是核心干系人,以及迭代的版本历史(如初稿、中稿、定稿)。
第二部分:需求背景与目标。回答项目概述、核心问题、用户故事、项目目标。
第三部分:方案概述。用 Mermaid 图展示核心业务流程、功能流程、信息架构。
第四部分:细节方案。页面原型与交互说明、边缘Case处理、非功能性需求。
第五部分:上线计划。排期、灰度发布策略。
最关键的是结构化 + 可视化。有了这个"单一事实来源",AI 的输出就会稳定很多,也不会出现需求爆炸的问题。
老师傅给你看了一份企业级 PRD 模板,里面详细列出了从初稿到定稿的迭代过程。
内部评审版(初稿):重点阐述需求背景、目标和核心价值。这时候不需要太详细,只要把"为什么要做"说清楚就行。
项目评审版(中稿):补充核心业务流程、功能流程图和原型交互说明。这时候要让开发、设计、测试都能看懂你要做什么。
开发前定稿(定稿):合入最终UI设计稿,补充边缘Case、埋点方案和上线计划。这时候文档要足够详细,开发可以直接照着做。
老师傅强调:"PRD 不是一蹴而就的,而是迭代出来的。早期版本想清楚'为什么',中期版本想清楚'是什么',最终版本想清楚'怎么做'。每一步都有评审和修改,避免到最后才发现大问题。"
除了迭代思维,需求管理也是产品经理的核心能力。
3.3 PRD 编写实战 🔴 - 完整模板 + 细节→代码因果关系 + 可视化技巧
从 PRD 到代码
老师傅告诉你,理解 AI 如何"阅读"和执行 PRD,能让你的文档写得更有效。AI 不会"脑补"模糊的地方,它严格按字面意思理解。如果 PRD 有歧义,AI 要么猜测(可能猜错),要么停下来问(增加对话轮次)。
当你把 PRD 给 AI 后,它会提取关键信息、构建数据模型、设计 API 接口、生成前后端代码。PRD 中的每一个细节都会影响最终代码的质量。
3.4 从 PRD 到代码 🟡 - 理解 AI 的"阅读"方式、PRD→代码的因果关系
需求管理与工具
在编写 PRD 的过程中,你还掌握了几个实用的需求管理技巧:
需求范围管理。明确"In-Scope(范围内)"和"Out-of-Scope(范围外)",有效管理团队预期,避免范围蔓延。
需求优先级排序。将需求拆解为具体的需求点,用表格列出需求ID、模块、描述、优先级、状态。
用户故事。以"作为一名<角色>,我想要<完成某项任务>,以便于<实现某个价值>"的格式描述需求。
SMART目标设定。项目目标要符合SMART原则——具体的、可衡量的、可实现的、相关的、有时限的。
此外,你还了解了 Markdown (.md) 和 Mermaid。Markdown 用于编写排版整齐的文本,Mermaid 用于通过文字代码绘制流程图。老师傅说,将这些文档提供给 AI,它生成的代码准确率显著提升。
老师傅补充道:"写 PRD 不是形式主义,而是为了训练你的问题定义能力。很多人直接让 AI'帮我做个功能',结果来回改很多次。但先写清楚目标、用户、业务场景、和交互逻辑,AI 往往一次就对了。差距就在想清楚。"
最后,老师傅还顺带提到了 Swagger。以后当项目变得复杂,利用 Swagger 自动生成接口文档,能更高效地确保文档与代码实现保持一致。
对了,记得让 AI 随时保持文档的更新。
下一步:关于项目说明书的详细编写,请查阅第四章:开发常识与技术栈中的"项目说明书 README.md"部分。
学习目标
完成本章后,你将能够:
- ✅ 掌握跟 AI 讨论需求时必须确认的细节清单
- ✅ 用产品验证三步法判断想法是否值得做
- ✅ 使用标准模板写出 AI 友好的 PRD
- ✅ 理解哪些细节会影响 AI 生成的代码质量
- ✅ 训练问题定义能力,提高 AI 协作效率
动手实践
现在,打开你最近想做的一个功能想法,在网页端跟 AI 按 3.2 的细节清单逐条确认。确认完后,用 3.3 的模板让 AI 生成 PRD 初稿。
你会发现:想得越清楚,AI 写得越准。
核心理念
"想清楚再动手,用文档训练思维。"
本章强调的是,在 AI 时代,问题定义能力比代码实现能力更重要。PRD 不是形式主义,而是产品思维的体现——从"为什么做"到"是什么"再到"怎么做",每一步都想清楚。有了结构化的 PRD 作为"单一事实来源",AI 就能成为高效的执行伙伴而不是猜谜者。
上一章:第二章:AI 使用说明书
下一章:第四章:你必须知道的开发基础