2.2.2 Pre-mortem失败模式分析:Vibe Coding项目避坑指南
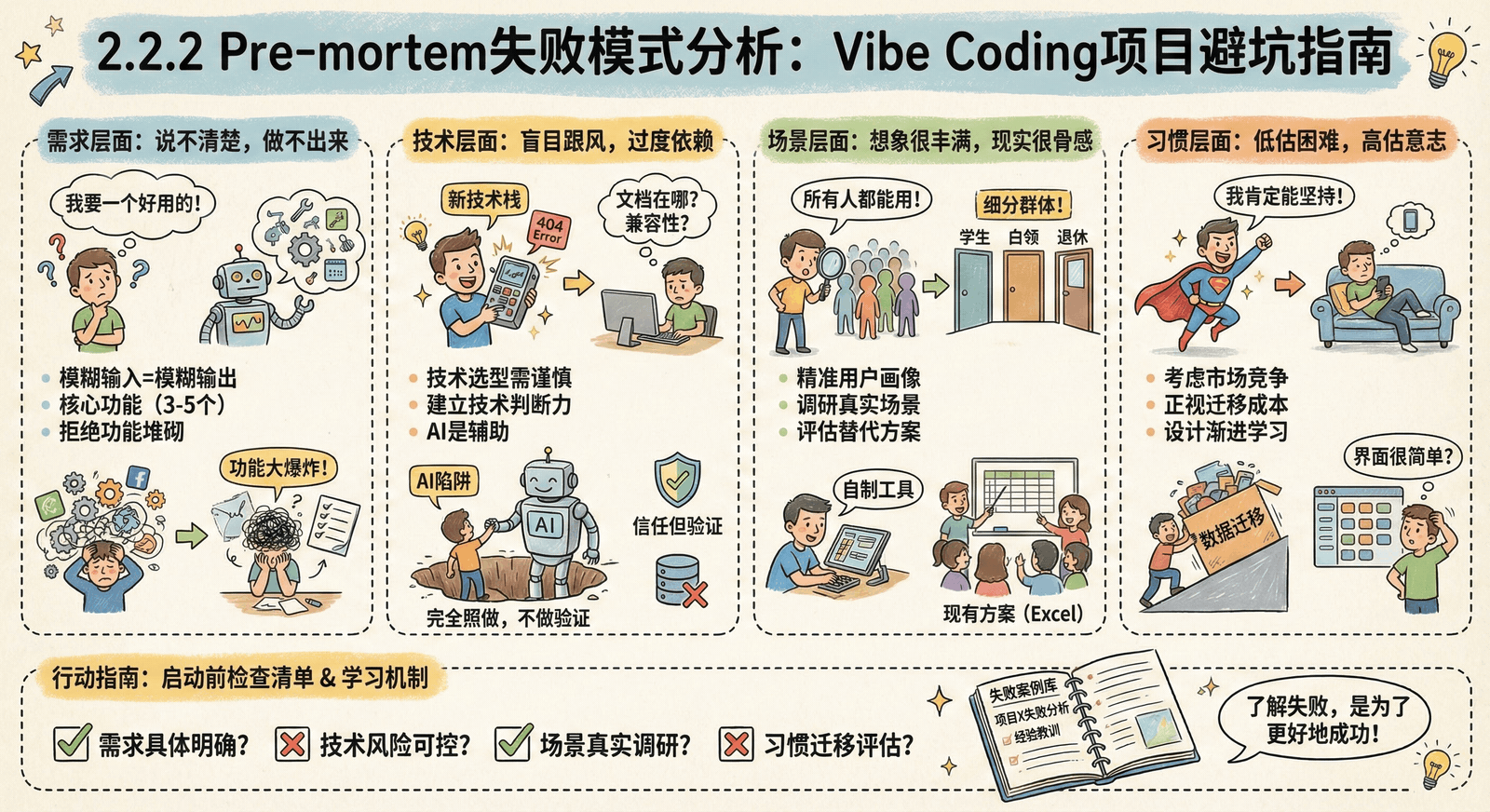
根据大量实践经验,Vibe Coding项目最常见的失败原因可以分为几大类。了解这些"前人踩过的坑",可以帮助你在做Pre-mortem时更全面地思考。
需求层面的失败模式
模式一:需求不清晰
典型表现:
- "帮我做一个好用的App"
- "我想要一个能提高效率的工具"
失败机制: AI无法读心。"好用"对你意味着什么?"提高效率"具体指哪个环节?模糊的输入只会得到模糊的输出。AI会按照它的理解去实现,而它的理解很可能和你想的完全不同。
实际案例: 用户让AI"做一个笔记App"。AI做出来的是一个功能完整的Markdown编辑器,支持语法高亮、导出PDF、多级文件夹……但用户只是想要一个能快速记录灵感的地方,一句话就够了。
Pre-mortem警示信号:
- 需求描述充满形容词(好用、高效、强大)
- 没有具体的使用场景
- 缺乏可衡量的成功标准
预防措施:
- 具体化描述:要做什么,在什么情况下,为谁服务
- 使用JTBD框架明确"雇佣"任务
- 设定可衡量的验收标准
模式二:功能复杂度爆炸
典型表现:
- 第一版就要20个功能
- "像XX产品一样,但要有这些改进……"
失败机制: 复杂度的增长是指数级的,不是线性的。
- 2个功能之间可能有1种交互关系
- 5个功能之间可能有10种交互关系
- 20个功能之间可能有190种交互关系
AI处理复杂系统时更容易出错,也更难发现和定位问题。
实际案例: 某用户一次性要求AI实现"用户注册、登录、个人中心、任务管理、团队协作、权限控制、数据统计、消息通知"。结果代码越改越乱,三天后整个项目变成了一团无法维护的意大利面条。
Pre-mortem警示信号:
- 功能列表超过10项
- 功能之间缺乏明确的优先级
- 试图一次性满足所有用户需求
预防措施:
- 严格限制核心功能(3-5个)
- 使用MVP思维,先验证核心价值
- 建立明确的"不做清单"
模式三:功能与任务脱节
典型表现:
- "我要做一个功能全面的工具"
- "参考XX产品,但要有这些特色"
失败机制: 没有从用户实际需求出发,而是在堆砌功能。
实际案例: 某用户想要做"项目管理工具",参考Jira等工具。但他没有分析自己团队的实际工作流程,结果做出来的工具功能虽然全面,但不符合团队习惯,最后还是回到了用Excel+微信群的方式。
Pre-mortem警示信号:
- 以"参考某产品"为设计起点
- 功能描述脱离具体使用场景
- 没有明确的核心用户画像
预防措施:
- 深入分析用户真实任务
- 先了解现有替代方案的优缺点
- 从解决具体问题出发,而非复制功能
技术层面的失败模式
模式一:技术选型不当
典型表现:
- "我要用最新的技术栈"
- "这个架构更先进"
失败机制: 追求"新"和"酷"而不是"合适"。新技术可能:
- 文档和社区资源不足
- 与AI工具的兼容性问题
- 学习成本过高,项目停滞
实际案例: 某用户坚持使用最新的前端框架,结果发现:
- AI生成的代码经常出现兼容性问题
- 遇到bug时,Stack Overflow上几乎没有解决方案
- 项目两个月后因为技术债务太多而放弃
Pre-mortem警示信号:
- 选择技术的理由是"新"、"酷"、"先进"
- 对技术的学习难度估计不足
- 没有考虑与AI工具的兼容性
预防措施:
- 选择成熟、有良好文档的技术
- 优先考虑AI工具支持度
- 评估自己的学习时间和维护成本
模式二:过度依赖AI
典型表现:
- "完全按照AI的建议做,不做任何调整"
- "AI说没问题,那肯定没问题"
失败机制: AI不是全知的。它会:
- 有时候"忘记"前面的上下文
- 在某些复杂问题上给出错误建议
- 缺乏对业务需求的理解
实际案例: 某用户完全按照AI的建议设计数据库结构,但没有进行合理性验证。结果在生产环境中发现性能问题,数据量一增长就卡死了。
Pre-mortem警示信号:
- 完全信任AI的输出,不做验证
- 遇到错误时不进行人工分析
- 缺乏基本的技术判断能力
预防措施:
- 保持"信任但验证"的态度
- 学习基础的技术判断能力
- 建立自己的决策框架,AI只是辅助工具
模式三:缺乏基础技术判断
典型表现:
- "AI说这个代码能运行,那肯定没问题"
- "我看不到报错,应该就没问题吧?"
失败机制: 缺乏基础的技术判断能力:
- 无法识别潜在的安全问题
- 不能理解代码的性能影响
- 遇到错误时无法有效调试
实际案例: 某用户的网站运行几个月后被黑客攻击。原因是AI生成的代码中存在SQL注入漏洞,但用户没有技术基础识别出来。
Pre-mortem警示信号:
- 对代码的安全性、性能一无所知
- 遇到问题时完全依赖AI
- 缺乏基本的测试和验证习惯
预防措施:
- 学习基础的安全和性能知识
- 建立测试验证流程
- 遇到不确定的情况时寻求专业意见
场景层面的失败模式
模式一:用户群体判断错误
典型表现:
- "所有人都能用"
- "这个市场需求很大"
失败机制: 过于宽泛的目标用户定义,导致:
- 需求冲突,无法满足所有人
- 产品缺乏针对性,没有核心用户群体
- 营销和推广策略无效
实际案例: 某用户想做"大学生学习工具",但没有细分。结果发现:
- 大一新生和大四毕业生的需求完全不同
- 文科生和理科生的学习方式不同
- 勤工学生和全日制学生的时间安排不同
最终产品因为"谁都不太满意"而失败。
Pre-mortem警示信号:
- 目标用户描述模糊("所有人"、"大众"等)
- 没有具体的用户画像
- 试图解决所有人的所有问题
预防措施:
- 细分目标用户群体
- 建立具体的用户画像
- 先服务一个小群体,验证需求后再扩展
模式二:场景假设错误
典型表现:
- "用户会每天使用这个功能"
- "这个功能肯定会受欢迎"
失败机制: 没有基于真实观察做出场景假设。
实际案例: 某用户认为"白领会每天使用运动记录App"。但实际调研发现:
- 大多数人只有周末才运动
- 工作日根本没有时间和精力
- 运动记录更多是社交性质的,而非个人习惯
Pre-mortem警示信号:
- 场景假设基于自己的想象
- 没有进行实际调研或观察
- 忽视用户实际的生活习惯
预防措施:
- 进行真实的用户调研
- 观察目标用户的实际行为
- 基于数据而非想象做假设
模式三:替代方案评估不足
典型表现:
- "现有的工具太难用了"
- "我的方案比现有的好多了"
失败机制: 低估现有方案的价值和用户习惯。
实际案例: 某用户认为"Excel表格管理客户信息太麻烦",想做专门的CRM工具。但他没有考虑到:
- Excel功能已经足够满足基本需求
- 用户已经建立了长期的使用习惯
- 学习新工具需要时间和成本
- 数据迁移的复杂性
结果CRM工具开发完成,但用户还是习惯用Excel。
Pre-mortem警示信号:
- 过度贬低现有方案
- 低估用户习惯的力量
- 忽略迁移成本和学习成本
预防措施:
- 深入分析现有方案的优缺点
- 理解用户使用现有方案的原因
- 评估迁移成本和收益
习惯层面的失败模式
模式一:高估持续使用意愿
典型表现:
- "我肯定会坚持使用的"
- "这个工具太有用了,不会放弃的"
失败机制: 对新工具的持续使用意愿过于乐观。
实际案例: 某用户开发了一个"完美的时间管理App",功能强大,界面精美。但一个月后发现:
- 手机里已经有很多类似App,功能重叠
- 新App需要手动输入数据,而其他App能自动同步
- 最终还是回到了最熟悉的老工具上
Pre-mortem警示信号:
- 基于个人喜好而非用户反馈
- 忽视市场竞争和替代方案
- 低估习惯的力量
预防措施:
- 考虑市场竞争情况
- 评估相比现有方案的优势
- 做小规模测试验证用户意愿
模式二:低估迁移成本
典型表现:
- "数据迁移很简单的"
- "只需要导入导出就行了"
失败机制: 低估从现有方案迁移到新方案的成本。
实际案例: 某用户认为"从Notion迁移到新笔记工具很简单"。但实际过程中发现:
- 数据格式不兼容,需要手动重新整理
- 丢失了Notion的数据库关联关系
- 团队协作的权限和流程需要重建
- 迁移花费的时间比预期长3倍
Pre-mortem警示信号:
- 对迁移过程的复杂性认识不足
- 忽略数据格式和功能差异
- 低估用户的情感投入
预防措施:
- 详细分析迁移过程
- 提供迁移工具和指南
- 考虑渐进式迁移策略
模式三:忽视学习成本
典型表现:
- "界面很简单,一看就会用"
- "功能不多,很容易学会"
失败机制: 低估用户学习新工具的认知成本。
实际案例: 某用户设计的界面在开发者看来"很简单直观"。但目标用户反馈:
- 找不到主要功能按钮
- 不理解图标的含义
- 不知道如何完成基本操作
最终因为"太难用"而被放弃。
Pre-mortem警示信号:
- 基于自己的技术理解判断易用性
- 缺乏目标用户的使用测试
- 忽视用户的知识背景差异
预防措施:
- 进行用户测试,观察实际使用过程
- 提供详细的使用指南和教程
- 设计渐进式的学习路径
失败模式检查清单
启动前检查
在开始项目前,对照以下问题进行检查:
需求层面:
- 我的需求描述足够具体吗?
- 我知道为谁解决什么问题吗?
- 核心功能是否控制在3-5个?
- 我有明确的"不做清单"吗?
技术层面:
- 我选择的技术适合当前需求吗?
- 我对基本的技术风险有了解吗?
- 我有代码审查和测试流程吗?
- 我知道如何验证AI生成的代码吗?
场景层面:
- 我的目标用户群体足够具体吗?
- 我做过实际的用户调研吗?
- 我了解现有替代方案吗?
- 我评估过迁移成本吗?
习惯层面:
- 我考虑过用户的持续使用意愿吗?
- 我评估过学习成本吗?
- 我有推广和留存计划吗?
- 我做过小规模验证吗?
进行中检查
在项目进行过程中,定期检查:
- 用户反馈是否与预期一致?
- 技术问题是否在可控范围内?
- 用户实际使用场景是否符合假设?
- 项目进展是否按计划进行?
失败模式学习指南
从失败中学习
- 记录失败案例:详细记录每个失败项目的情况
- 分析根本原因:找出表面问题背后的深层原因
- 总结经验教训:提炼出可以应用到未来项目的教训
- 建立检查清单:将教训转化为具体的预防措施
建立失败案例库
建议建立一个个人失败案例库,包含:
- 项目背景和目标
- 失败的具体表现
- 失败原因分析
- 学到的教训
- 预防措施
定期回顾和更新
定期回顾失败案例库:
- 每季度回顾一次
- 根据新的经历更新案例
- 分享给团队成员共同学习
- 将教训转化为具体的流程和制度
下一步
掌握了常见的失败模式后,接下来我们将学习:
- 2.2.3 Pre-mortem实战指南 - 学习具体的操作步骤、模板和工具
通过了解这些失败模式,你可以在项目启动前就识别潜在风险,大大提高项目成功率。记住:了解失败是为了更好地成功。