🎨 Vibecoding 案例分享:零代码打造 AI 绘本生成器
面向人群:无编程基础的纯小白
项目周期:约 2 周(边学边做)
最终成果:一个能把任意文档自动转换成儿童绘本的 AI 应用
🖼️ 效果展示

上图展示了一本由 AI 自动生成的儿童绘本《狐狸大冒险》,包含封面、内容页、互动页、角色参考图等完整内容。
📚 学习路线图
| 阶段 | 目标 | 时间 | 难度 |
|---|---|---|---|
| 🎯 Demo 阶段 | 5 分钟跑通第一个 AI 应用 | 5 分钟 | ⭐ |
| 🚀 上手阶段 | 完成完整的绘本生成器 | 1-2 天 | ⭐⭐ |
| ⚡ 优化阶段 | 解决实际问题,提升质量 | 持续 | ⭐⭐⭐ |
| 🌊 深水区 | 理解原理,举一反三 | 进阶 | ⭐⭐⭐⭐ |
🎯 第一阶段:Demo(5 分钟看到效果)
核心理念:别看理论,先动手!5 分钟内让你看到效果。
Step 1:下载 AI 编辑器(2 分钟)
- 打开浏览器,搜索 "Cursor 下载" 或 "Windsurf 下载"
- 下载安装包,双击安装
- 用邮箱注册账号
Step 2:创建项目文件夹
在电脑上随便找个地方,新建一个文件夹:我的AI绘本
Step 3:复制这段话给 AI
打开 Windsurf/Cursor,按 Cmd+L(Mac)或 Ctrl+L(Windows)打开 AI 对话框。
复制粘贴这段话:
我想做一个 AI 绘本生成器。
请帮我创建一个最简单的版本:
1. 用 Python + Gradio 做界面
2. 用户输入一段文字描述
3. 调用 AI 生成一张绘本风格的图片
4. 显示出来
先帮我创建项目结构和必要的文件。Step 4:跟着 AI 做(2 分钟)
AI 会告诉你:
- 创建哪些文件
- 安装什么依赖
- 怎么运行
你只需要:点击 AI 给的"Apply"按钮,它会自动帮你创建文件。
Step 5:接入 Nano Banana Pro API
Nano Banana Pro 是一个强大的 AI 图片生成服务,用于生成绘本插图。
1. 申请 API Key
- 打开 https://grsai.com (注: 这个网站目前是我用着相对性价比感觉比较高的nano banana pro模型服务商, 如果有其他更好的模型服务商, 欢迎在评论区分享)
- 注册账号并登录
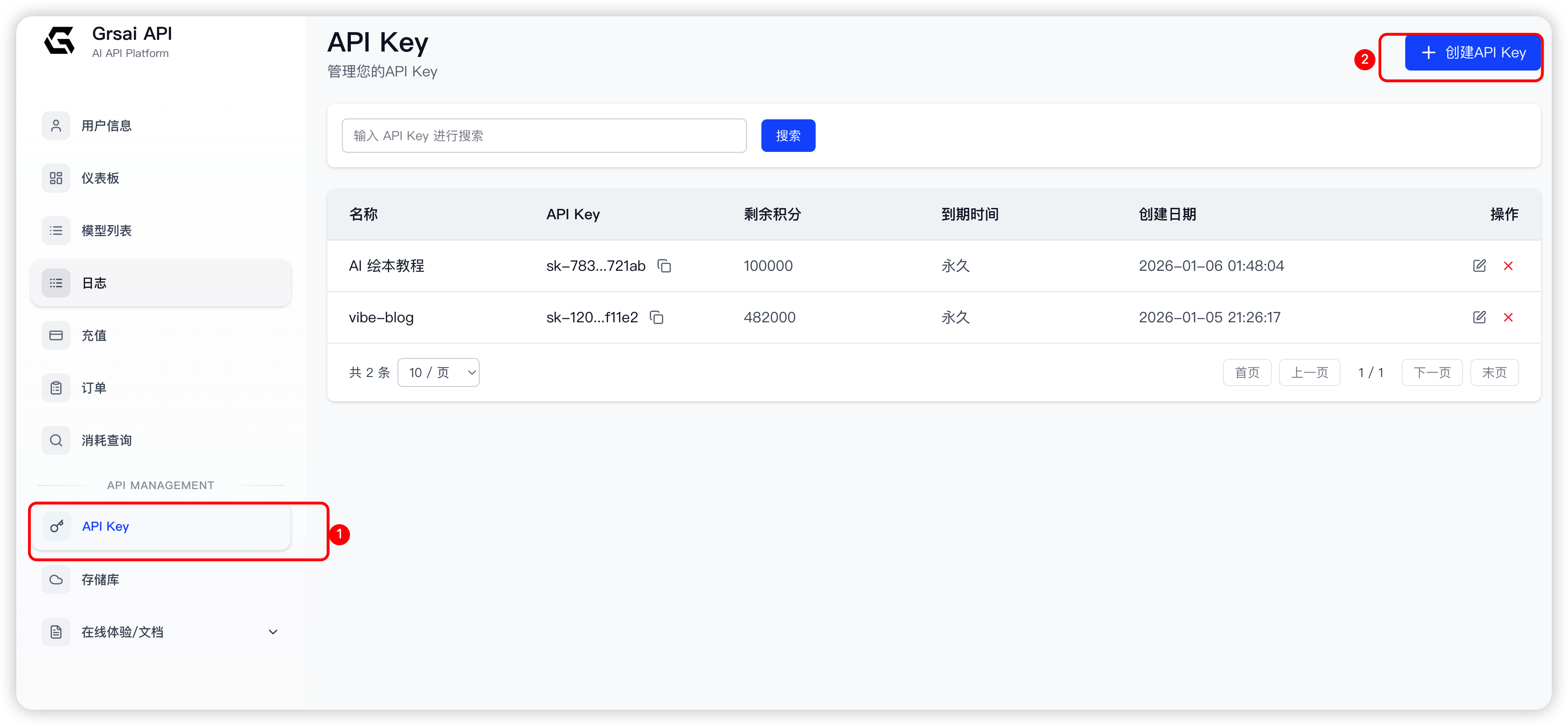
- 进入控制台,创建 API Key(按需购买积分, 按照我的经验来说, 10 元以内对于测试项目是完全够用的, 非广告推销, 只是为了测试与接入nano banana pro做图片生成功能使用)
- 重要:妥善保存你的 API Key,不要泄露!
2. 配置环境变量
在项目根目录创建 .env 文件(如果没有的话),添加以下配置:
# Nano Banana Pro API(用于 AI 图片生成)
NANO_BANANA_API_KEY=sk-7832cba5ad4e4119bbd1bf756ea721ab(这里提供一个可直接用来做测试的 api_key, 有额度限制, 建议实践的同学后续换成自己的 api_key,注意不要泄露,避免被他人使用)
NANO_BANANA_API_BASE=https://grsai.com
NANO_BANANA_MODEL=nano-banana-pro| 配置项 | 说明 | 默认值 |
|---|---|---|
NANO_BANANA_API_KEY | 你的 API 密钥 | 必填 |
NANO_BANANA_API_BASE | API 服务地址 | https://grsai.com |
NANO_BANANA_MODEL | 使用的模型 | nano-banana-pro |
可选模型:
nano-banana-fast- 快速生成,质量一般nano-banana-pro- 专业版(推荐)
3. 让 AI 帮你接入
把下面这段话复制给 AI:
请帮我接入 Nano Banana Pro 图片生成 API。
API 信息:
- 基础 URL: https://grsai.com
- 绘画接口: POST /v1/draw/nano-banana
- 结果查询: POST /v1/draw/result
- 认证方式: Bearer Token (放在 Authorization header)
请求参数:
- model: 模型名称,如 "nano-banana-pro"
- prompt: 图片描述
- aspectRatio: 图片比例,如 "16:9"
- imageSize: 图片大小,如 "2k"
返回结果是异步的,需要轮询 /v1/draw/result 接口获取生成结果。
请帮我:
1. 创建一个 image_service.py 服务类
2. 从 .env 读取 API Key
3. 实现生成图片和等待结果的逻辑AI 会帮你生成完整的接入代码!
如果AI生成的代码有错误, 可以打开接入文档:https://grsai.com/dashboard/documents/nano-banana, 然后把所有的 api 调用信息copy 过来, 让AI帮你实现具体的接入逻辑, 而你只需要配置下 Token 就可以了。 
Step 6:运行看效果!
AI 会告诉你运行命令,通常是:
pip install gradio openai
python app.py然后打开浏览器,访问 http://localhost:7860,你就能看到一个简单的界面了!
🎉 恭喜!你已经做出了第一个 AI 应用!
Demo 阶段小结
| 你学到了什么 | 说明 |
|---|---|
| AI 编辑器 | Cursor/Windsurf 是你的"程序员朋友" |
| 对话式开发 | 用自然语言描述需求,AI 帮你写代码 |
| 快速验证 | 先做最小版本,看到效果再继续 |
🚀 第二阶段:上手(1-2 天完成完整项目)
上面的 Demo 只是开胃菜,下面是完整的项目开发过程。
📖 什么是 Vibecoding?
Vibecoding = 用自然语言告诉 AI 你想要什么,让 AI 帮你写代码。
你不需要懂编程语法,只需要:
- 清晰描述你的想法
- 和 AI 对话迭代
- 测试并反馈问题
就像和一个程序员朋友聊天,告诉他你想做什么,他帮你实现。
🎯 项目目标
痛点
- 幼儿园老师想把教案变成绘本给小朋友看,但不会画画
- 家长想把孩子喜欢的故事做成图文并茂的绘本
- 培训机构想把枯燥的知识点变成有趣的图画书
解决方案
上传一个文档 → AI 自动生成一本完整的绘本
包含:故事大纲、角色设计、每页插图、最终 PPT/PDF
🛠️ 完整实战过程
第一轮对话:从零开始
我对 AI 说:
"我想做一个 AI 绘本生成器。用户上传一个 PDF 文档,系统自动把它变成一本儿童绘本。需要有:文档解析、大纲生成、图片生成、导出 PDF 这几个功能。用 Python Flask 做后端。"
AI 帮我生成了:
- 项目目录结构
- Flask 应用入口文件
- 数据库模型(存储绘本信息)
- 基础 API 接口
第二轮对话:完善文档解析
我对 AI 说:
"文档解析这块,我想支持 PDF、Word、TXT 格式。PDF 可能有图片,需要用 OCR 识别。帮我接入mineru 这个 OCR 服务。"
AI 帮我实现了:
- 文件上传接口
- 根据文件类型选择不同解析方式
- 调用 mineru API 解析 PDF
- 提取文档中的图片并生成描述
如何申请与接入 mineru API呢?
全能的文档解析神器全能的文档解析神器
精准解析 高效提取 全面助力AI Ready数据自由
打开网址, 注册账号, 进入首页. 
点击 'API',先进行 API 申请, "MinerU API 申请问卷", 提交后很快就会收到通过的申请.
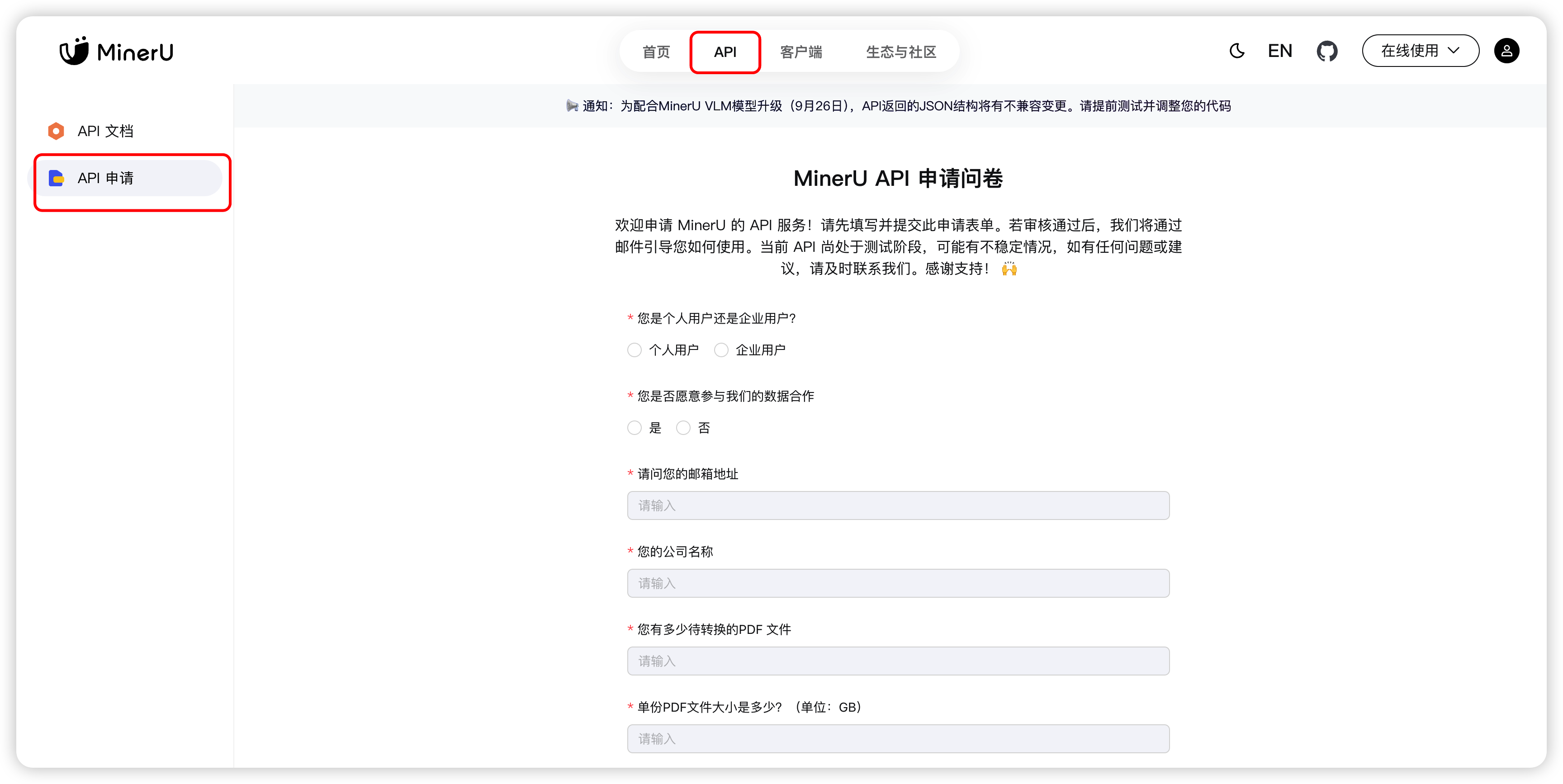
申请通过后,就可以创建 API Token 了(注意, 该 Token 要保存好,后面要用到, 且不要轻易泄漏)。 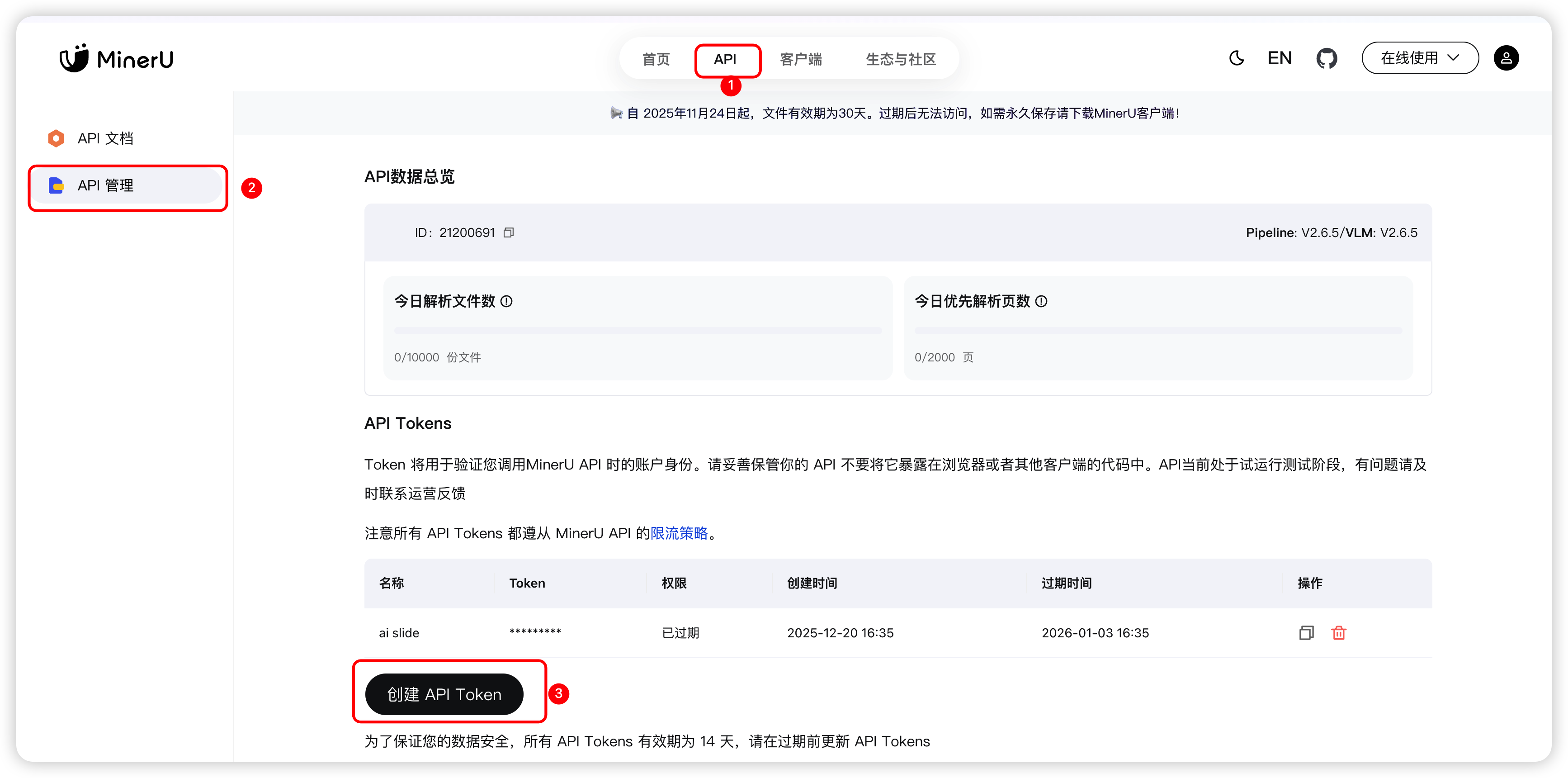
mineru当前每天支持 10000 次的免费调用,基本可以满足我们的测试需求!
在接入阶段, 将API文档页中关于如何接入 API 的全部内容 copy 过来, 让AI帮我实现具体的接入逻辑, 而你只需要配置下 Token 就可以了。 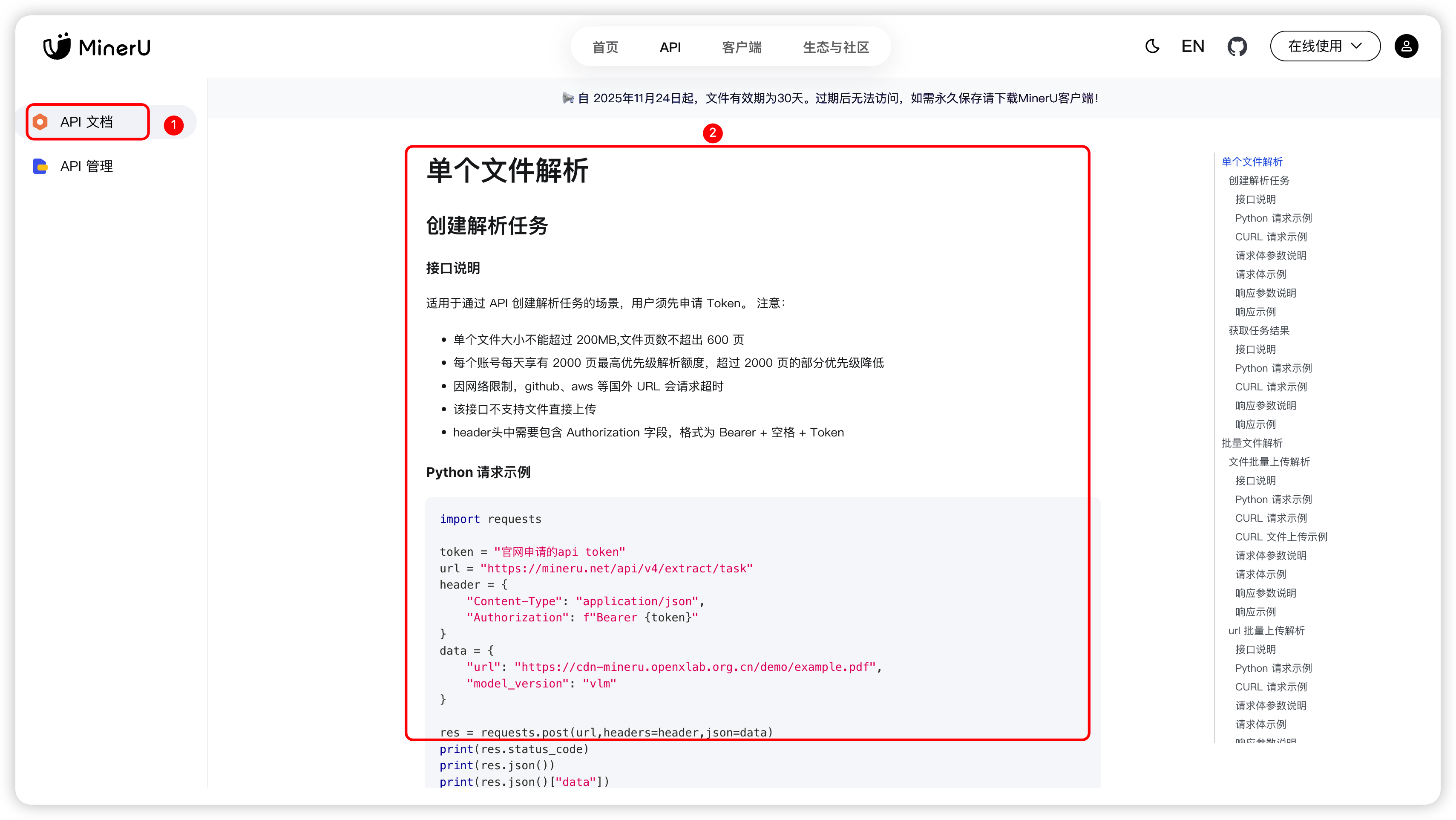
第三轮对话:设计 Prompt(最关键!)
我对 AI 说:
"大纲生成的 Prompt 不太好,生成的内容太像 AI 写的,没有童趣。我想要:
- 让 AI 扮演'世界级儿童绘本设计师'
- 每页要有叙事目标、关键内容、视觉画面、布局结构
- 避免 AI 废话,比如'不仅仅是 X,而是 Y'这种
- 封面要有冲击力,封底要有仪式感"
AI 帮我优化了 Prompt:
你是一位世界级的儿童绘本设计师和故事讲述者。
你制作的绘本能根据源素材和目标受众进行调整。
凡事皆有故事,而你要找到最佳的讲述方式。
每一页必须包含以下 4 个部分:
// NARRATIVE GOAL (叙事目标)
// KEY CONTENT (关键内容)
// VISUAL (视觉画面)
// LAYOUT (布局结构)
**至关重要 (CRITICAL):**
- 避免"标题:副标题"格式,这很 AI 感
- 禁止"不仅仅是 [X],而是 [Y]"这种废话
- 封底不要用"谢谢观看",要有设计感的结束语第四轮对话:解决角色一致性问题
我发现的问题:
"生成的绘本里,同一个小狐狸在不同页面长得不一样!第一页是橙色的,第三页变成红色了。"
我对 AI 说:
"怎么让角色在每一页都保持一致?"
AI 给出的方案:
- 先生成一张"角色设定图"(正面、侧面、不同表情)
- 生成每一页时,把角色设定图作为参考传给 AI
- 在 Prompt 里强调"必须和参考图保持一致"
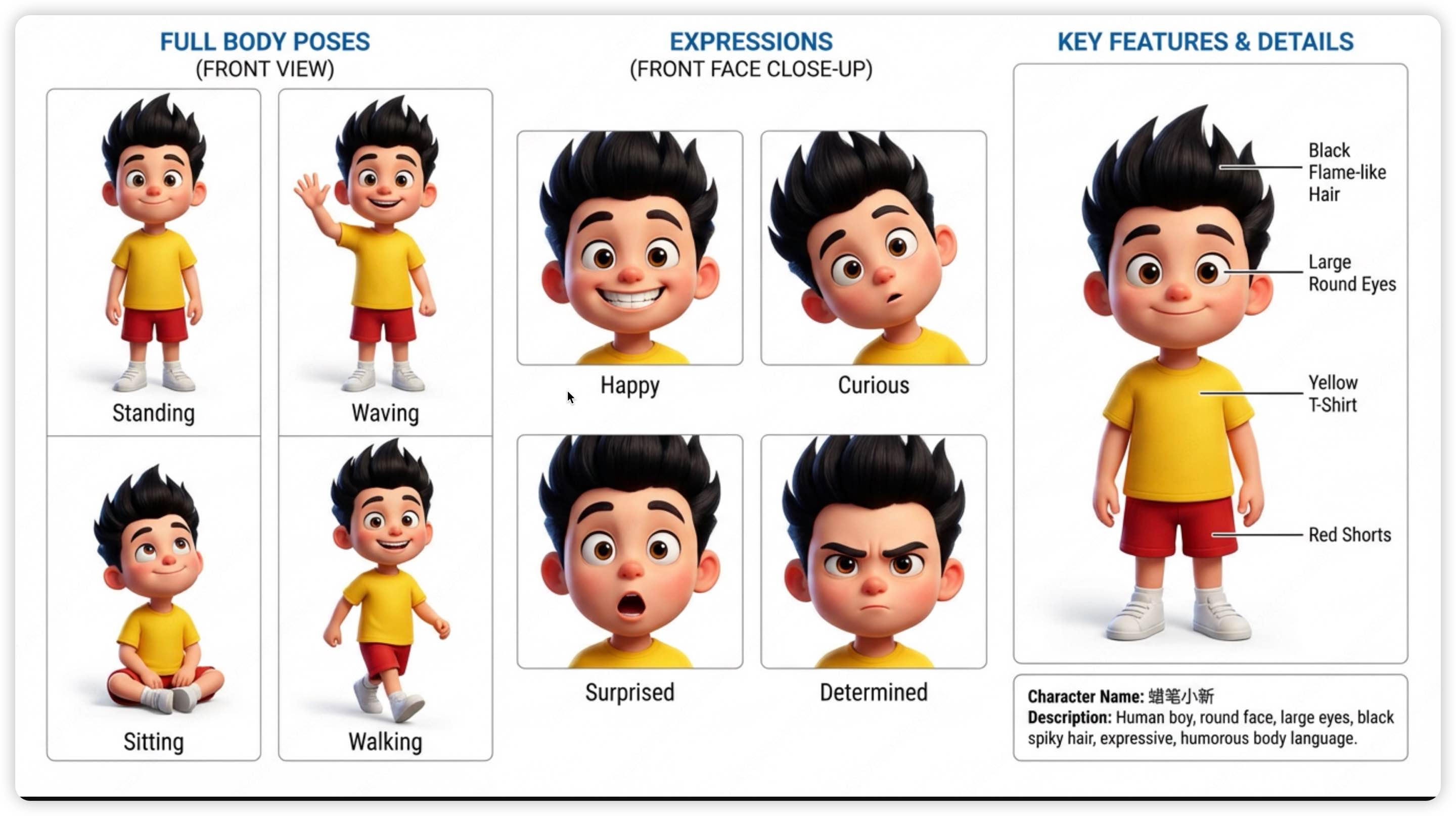
角色设定图示例:包含全身姿势(站立、挥手、坐下、行走)、面部表情(开心、好奇、惊讶、坚定)、关键特征标注(发型、眼睛、服装)
## 🎭 Character Consistency (CRITICAL)
You MUST maintain character consistency with the reference image.
- Keep the same: face shape, eye color, hair style, clothing
- Only change: pose, expression, and interaction with the scene第五轮对话:添加实时进度
我对 AI 说:
"生成一本绘本要好几分钟,用户干等着体验很差。能不能实时显示进度?比如'正在解析文档...'、'正在生成第 3 页...'这样。"
AI 帮我实现了 SSE(服务器推送事件):
- 用户创建任务后,获得一个 task_id
- 前端通过 SSE 订阅进度
- 后端每完成一步就推送进度更新
- 每生成一张图就实时显示出来
第六轮对话:支持用户上传照片
我对 AI 说:
"有个新需求:用户可以上传自己的照片(比如孩子的照片),让 AI 把照片融入到绘本插图里。比如画一个卡通场景,但里面有真实的照片。"
AI 帮我设计了 Mixed Media 方案:
🖼️ Reality Layer (真实照片层)
└── 用户上传的照片,保持 100% 真实质感
🦊 Illustration Layer (插画层)
└── AI 生成的卡通角色和场景
🌓 The Glue (融合层)
└── 光影统一、边缘交互上手阶段小结
| 你学到了什么 | 说明 |
|---|---|
| 迭代开发 | 一轮对话解决一个问题,逐步完善 |
| Prompt 设计 | 好的提示词决定 AI 输出质量 |
| 问题描述 | 遇到问题要描述现象,不要猜原因 |
⚡ 第三阶段:优化(解决实际问题)
项目跑起来了,但会遇到各种问题。这一节教你怎么解决。
💡 Vibecoding 的关键技巧
1. 先描述"做什么",再说"怎么做"
❌ 错误示范:
"帮我写一个 Flask 路由,用 POST 方法,接收 multipart/form-data..."
✅ 正确示范:
"我需要一个文件上传功能,用户可以上传 PDF 文件,系统保存后返回一个任务 ID"
2. 遇到问题,描述现象而非猜测原因
❌ 错误示范:
"数据库连接池是不是有问题?"
✅ 正确示范:
"上传文件后,有时候会报错'connection timeout',大概 10 次里有 2 次"
3. 用具体例子说明期望
❌ 错误示范:
"生成的内容不够好"
✅ 正确示范:
"现在生成的标题是'狐狸的故事:一个关于友谊的冒险',我想要更有童趣的,比如'嘿!这就是你要找的狐狸入门指南'"
4. 分步骤迭代,不要一次说太多
❌ 错误示范:
"帮我做一个完整的绘本系统,要有用户登录、文件上传、AI 生成、导出 PDF、分享到微信..."
✅ 正确示范:
"我们先做文件上传功能。用户上传一个 PDF,系统保存到本地,返回文件路径。"
🚨 踩坑指南:我遇到的问题和解决方案
这些坑我都踩过,分享出来让你少走弯路。
坑 1:API Key 泄露
问题:把 API Key 写在代码里,上传到 GitHub,被人盗用,一夜之间扣了 500 块。
解决:
# ❌ 错误:直接写在代码里
api_key = "sk-xxxxxxxxxxxxx"
# ✅ 正确:写在 .env 文件里
# .env 文件(不要上传到 GitHub)
OPENAI_API_KEY=sk-xxxxxxxxxxxxx
# 代码里这样读取
import os
api_key = os.getenv("OPENAI_API_KEY")记住:创建 .gitignore 文件,把 .env 加进去。
坑 2:生成的图片风格不统一
问题:第一页是卡通风格,第二页变成写实风格了。
解决:在每个图片生成的 Prompt 里,都加上风格描述。
# ❌ 错误:只描述内容
prompt = "画一只狐狸在森林里"
# ✅ 正确:内容 + 风格
prompt = """
画一只狐狸在森林里。
风格要求:
- 迪士尼皮克斯 3D 动画风格
- 明亮温暖的色调
- 角色有大眼睛、圆润的线条
- 背景简洁,有柔和的光线
"""坑 3:角色长得不一样
问题:同一个角色,每一页长得都不一样。
解决:
- 先生成一张角色参考图
- 每次生成页面时,把参考图传给 AI
- 在 Prompt 里强调"必须和参考图一致"
坑 4:生成太慢,用户以为卡死了
问题:生成一本绘本要 5 分钟,用户盯着白屏。
解决:
- 加进度条
- 每完成一步就更新状态
- 每生成一张图就立刻显示
坑 5:Prompt 太长,AI 忘记前面的要求
问题:Prompt 写了 2000 字,AI 只记住了最后几句。
解决:
- 把最重要的要求放在 Prompt 的开头和结尾
- 用
**加粗**或⚠️ 重要标记关键要求 - 把长 Prompt 拆成多个短 Prompt
🎯 Prompt 模板:拿来就用
这些是我调试好的 Prompt,直接复制使用。
模板 1:大纲生成 Prompt
你是一位世界级的儿童绘本设计师和故事讲述者。
## 任务
根据以下文档内容,设计一本 10-15 页的儿童绘本大纲。
## 文档内容
{这里粘贴文档内容}
## 输出要求
为每一页提供:
1. **标题**:叙事性标题(不是"标题:副标题"格式)
2. **叙事目标**:这一页在故事中的作用
3. **关键内容**:要展示的文字
4. **视觉画面**:场景、角色动作、表情
5. **布局**:构图建议
## 禁止事项
- 禁止使用"让我们一起..."、"小朋友们..."等说教语气
- 禁止"不仅仅是X,而是Y"等 AI 味道的句式
- 禁止以"谢谢观看"结尾
## 输出格式
JSON 格式,便于程序解析模板 2:图片生成 Prompt
你是一位专业的儿童绘本插画师。
## 任务
为绘本的第 {页码} 页绘制插图。
## 页面内容
标题:{标题}
文字:{内容}
场景:{视觉描述}
## 风格要求
- 迪士尼皮克斯 3D 动画风格
- 明亮温暖的色调,主色调为橙色、绿色、蓝色
- 角色有大眼睛、圆润的线条
- 背景简洁,有柔和的光线
- 16:9 比例,4K 分辨率
## 角色一致性(重要!)
主角必须和参考图保持一致:
- 相同的:脸型、眼睛颜色、发型、服装
- 可以变化的:姿势、表情、与场景的互动
## 禁止
- 禁止出现 Markdown 符号(# * 等)
- 禁止文字模糊不清
- 禁止风格突变模板 3:角色设定图 Prompt
创建一张角色设定图(Character Reference Sheet)。
## 角色信息
名称:{角色名}
描述:{外观描述}
## 设定图要求
1. 展示角色的 3 个角度:正面、3/4 侧面、侧面
2. 展示 3-4 种表情:开心、好奇、惊讶、思考
3. 展示全身和面部特写
4. 使用干净的白色背景
5. 标注关键特征(发色、眼睛颜色、服装细节)
## 风格
{风格描述,如"迪士尼皮克斯 3D 动画风格"}
## 布局
横向 16:9,像专业的角色设计稿一样排列优化阶段小结
| 你学到了什么 | 说明 |
|---|---|
| 沟通技巧 | 怎么和 AI 高效沟通 |
| 踩坑经验 | 常见问题的解决方案 |
| Prompt 模板 | 可复用的提示词模板 |
🌊 第四阶段:深水区(理解原理,举一反三)
这一节帮你理解"为什么",而不只是"怎么做"。理解了设计思路,你就能举一反三,做出自己的 AI 应用。
📊 项目成果展示
功能清单
| 功能 | 描述 | 状态 |
|---|---|---|
| 📄 文档解析 | 支持 PDF/Word/TXT,自动提取文字和图片 | ✅ |
| 🎨 风格选择 | 疯狂动物城、吉卜力、皮克斯等多种风格 | ✅ |
| 📝 大纲生成 | AI 自动规划绘本结构和每页内容 | ✅ |
| 🦊 角色一致性 | 生成角色参考图,确保全书角色统一 | ✅ |
| 🖼️ 图片生成 | 并行生成所有页面插图 | ✅ |
| 📸 照片融合 | 支持将真实照片融入插画场景 | ✅ |
| 📚 导出 PPT | 一键导出可编辑的 PPTX 文件 | ✅ |
| 🎬 动画生成 | 可选生成绘本动画视频(带旁白) | ✅ |
技术栈(你不需要懂,AI 帮你选的)
- 后端:Python Flask
- 数据库:SQLite(开发)/ PostgreSQL(生产)
- 文档解析:MinerU OCR
- AI 模型:GPT-4o(文本)+ GPT-Image-1 / Gemini(图片)
- 动画生成:可灵 AI / 通义万象
🏗️ 项目架构
小白版(快速理解)
你上传一个 PDF/Word 文档
↓
┌─────────────────────────────────────┐
│ 第 1 步:文档解析 │
│ 把文档里的文字和图片提取出来 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 第 2 步:AI 生成绘本大纲 │
│ 决定分几页、每页讲什么、画什么 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 第 3 步:AI 生成角色参考图 │
│ 确保主角在每一页长得一样 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 第 4 步:AI 批量生成每页插图 │
│ 根据大纲,一页一页画出来 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 第 5 步:导出成品 │
│ 打包成 PPT/PDF,还能生成动画视频! │
└─────────────────────────────────────┘
↓
一本完整的 AI 绘本诞生!🎉系统架构图
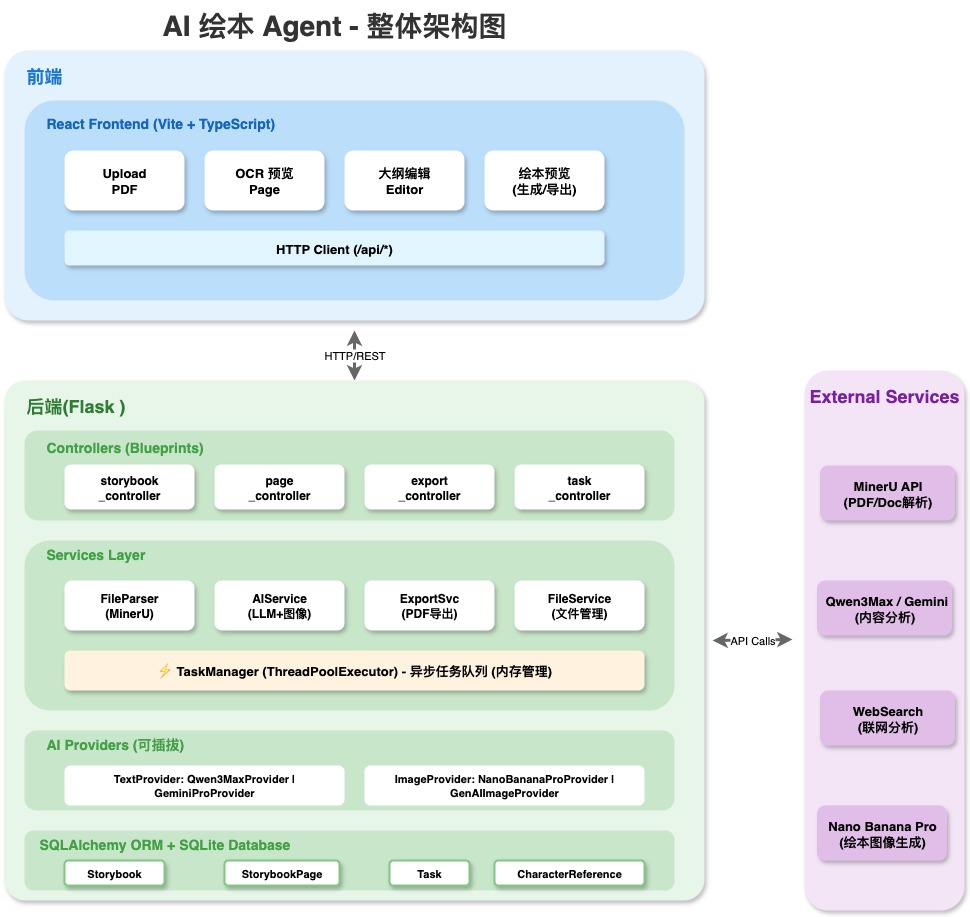
架构说明:
| 层级 | 组件 | 说明 |
|---|---|---|
| 前端 | React + Vite + TypeScript | Upload PDF、OCR 预览、大纲编辑、绘本预览/导出 |
| 后端 Controllers | storybook / page / export / task | 4 个 Blueprint 路由模块 |
| Services 层 | FileParser / AIService / ExportSvc / FileService | 核心业务逻辑 + TaskManager 异步任务队列 |
| AI Providers | TextProvider / ImageProvider | 可插拔的 AI 模型适配层 |
| 数据库 | SQLAlchemy + SQLite | Storybook / StorybookPage / Task / CharacterReference |
| 外部服务 | MinerU / Qwen / Gemini / WebSearch / Nano Banana Pro | PDF 解析、内容分析、联网搜索、图像生成 |
完整技术流程(进阶版)
┌─────────────────────────────────────────────────────────────────────────────┐
│ AI 绘本生成完整流程 │
└─────────────────────────────────────────────────────────────────────────────┘
用户输入
├── 主题/文档内容 (parsed_content)
├── 风格关键词 (style_keyword): "疯狂动物城"、"宫崎骏"
├── 参考图片 (reference_images): 风格参考图
└── 素材图片 (source_images): 需要嵌入绘本的真实照片
↓
┌─────────────────────────────────────────────────────────────────────────────┐
│ Stage 1: 风格生成 (Style Generator) │
├─────────────────────────────────────────────────────────────────────────────┤
│ 输入: │
│ - theme (主题) │
│ - style_keyword (风格关键词) │
│ - reference_images (参考图片) ← 多模态 LLM 分析图片风格 │
│ - target_audience (目标受众) │
│ │
│ 输出: │
│ - style_config JSON (设计美学、配色、字体、视觉元素、角色风格) │
└─────────────────────────────────────────────────────────────────────────────┘
↓ style_config
┌─────────────────────────────────────────────────────────────────────────────┐
│ Stage 2: 大纲生成 (Outline Generator) │
├─────────────────────────────────────────────────────────────────────────────┤
│ 输入: │
│ - parsed_content (文档内容) │
│ - background_knowledge (联网搜索的背景知识) │
│ - style_config (来自 Stage 1) │
│ - source_images (素材图片列表) ← 告知 LLM 有多少张图片可用 │
│ - user_prompt, target_audience, subject, theme_character │
│ │
│ 输出: │
│ - 完整绘本大纲 JSON │
│ - title, style_config, sections │
│ - 每页 slide: title, narrative_goal, content, visual_description, │
│ layout, embedded_images (如 ["IMG_1", "IMG_2"]) │
└─────────────────────────────────────────────────────────────────────────────┘
↓ 大纲 + embedded_images
┌─────────────────────────────────────────────────────────────────────────────┐
│ Stage 3: 图片生成 (Image Generator) │
├─────────────────────────────────────────────────────────────────────────────┤
│ 对每个 slide 执行: │
│ │
│ 1. 检查 embedded_images 是否为空 │
│ ├── 有图片 → 使用 REALITY_PATCH_TEMPLATE │
│ └── 无图片 → 使用 STANDARD_TEMPLATE │
│ │
│ 2. 拼接视觉指令: │
│ - style_config.design_aesthetic │
│ - slide.visual_description │
│ - Reality Layer / Illustration Layer / The Glue (如有图片) │
│ │
│ 3. 调用多模态 API: │
│ - prompt: 拼接后的视觉指令 │
│ - images: source_images 中对应的真实图片 (IMG_1 → source_images[0]) │
│ │
│ 输出: │
│ - 每页的生成图片 (Mixed Media: 插画 + 真实照片融合) │
└─────────────────────────────────────────────────────────────────────────────┘
↓
最终绘本 (图片 + 文字)🧠 核心设计原则
原则 1:流水线思维 —— 把大问题拆成小步骤
问题:直接让 AI "把文档变成绘本" 太模糊,AI 不知道从哪下手。
解决:拆成 5 个清晰的步骤,每一步只做一件事。
❌ 错误思路:一步到位
"AI,把这个 PDF 变成绘本"
→ AI 懵了,不知道要做什么
✅ 正确思路:流水线
步骤1:提取文字 → 步骤2:生成大纲 → 步骤3:画角色 → 步骤4:画每页 → 步骤5:打包
→ 每一步都很清晰,AI 能精准执行原则 2:Prompt 是灵魂 —— 好的提示词决定一切
类比:Prompt 就像你给厨师的菜谱
- 菜谱写"做一道好吃的菜" → 厨师随便做
- 菜谱写"用鸡胸肉、西兰花、蒜末,先煎后炒,少盐多蒜" → 厨师精准执行
| 技巧 | 说明 | 示例 |
|---|---|---|
| 角色扮演 | 让 AI 进入专业角色 | "你是世界级儿童绘本设计师" |
| 结构化输出 | 规定输出格式 | "每页必须包含:叙事目标、关键内容、视觉画面、布局" |
| 负面约束 | 告诉 AI 不要做什么 | "禁止使用'不仅仅是X,而是Y'这种句式" |
原则 3:分层架构 —— 让代码像乐高积木
┌─────────────────────────────────────────────────────────────┐
│ 🎨 界面层 (Gradio) - 用户看到的界面 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 🔧 服务层 (Services) - 具体的业务逻辑 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 🤖 AI 层 (Providers) - 和各种 AI 模型通信 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 💾 数据层 (Database) - 存储绘本信息 │
└─────────────────────────────────────────────────────────────┘好处:想换一个 AI 模型?只改 AI 层,其他层不用动。
原则 4:异步处理 —— 别让用户干等
❌ 同步处理:点击"生成" → 白屏 5 分钟 → 突然全部出来
✅ 异步处理:点击"生成" → "正在解析文档..." → "正在生成大纲..."
→ "第 1 页生成完成 ✓" [显示图片] → "第 2 页生成完成 ✓" [显示图片]📊 项目文件结构(参考)
AI绘本/
├── backend/ # 后端代码
│ ├── app.py # Flask 应用入口
│ ├── config.py # 配置文件
│ ├── requirements.txt # Python 依赖
│ ├── .env # 环境变量(API Key 放这里)
│ │
│ ├── controllers/ # API 接口
│ ├── services/ # 业务逻辑
│ ├── models/ # 数据模型
│ ├── prompts/ # Prompt 模板
│ └── utils/ # 工具函数
│
├── uploads/ # 上传的文件
├── outputs/ # 生成的绘本
└── docs/ # 文档| 文件/文件夹 | 作用 | 小白理解 |
|---|---|---|
app.py | 程序入口 | 双击运行的那个文件 |
.env | 密钥 | API Key 放这里,不要上传 |
services/ | 逻辑 | 真正干活的代码 |
prompts/ | 提示词 | 给 AI 的指令模板 |
📝 常见问题
Q: 我完全不懂代码,真的能做出来吗?
A: 可以!关键是:把需求描述清楚、遇到问题及时问 AI、不要怕报错。
Q: 需要花多少钱?
A: AI 编辑器免费版够用,API 测试阶段大概几十块,开发阶段用本地电脑免费。
Q: 生成一本绘本要多久?
A: 文档解析 10-30 秒 + 大纲生成 20-40 秒 + 图片生成 2-5 分钟 = 总计约 3-6 分钟
🔗 相关资源
- 项目代码:就在这个文件夹里
- API 文档:
docs/API文档-文件上传与解析.md - SSE 文档:
docs/SSE-API文档.md - Prompt 设计:
docs/AIPromot-AI 绘本生成完整流程.md
🌟 进阶方向
| 方向 | 说明 | 难度 |
|---|---|---|
| 多轮对话 | 让用户和 AI 对话修改绘本 | ⭐⭐⭐ |
| 更多导出格式 | 视频(带旁白)、电子书(ePub) | ⭐⭐ |
| 模板市场 | 预设多种绘本模板 | ⭐⭐⭐ |
| 商业化 | 用户系统、付费功能 | ⭐⭐⭐⭐ |
深水区小结
| 你学到了什么 | 说明 |
|---|---|
| 架构思维 | 怎么设计一个可扩展的系统 |
| 设计原则 | 流水线、分层、异步处理 |
| 进阶方向 | 做完之后还能往哪走 |
💬 最后的话
Vibecoding 不是让你变成程序员,而是让你不需要成为程序员也能创造软件。
这个 AI 绘本项目,从想法到成品,全程都是和 AI 对话完成的。
你也可以。
本文档由 Vibecoding 生成,用 AI 写关于 AI 的故事 🤖