测试「Bash 就够了」假设:SQL vs Bash 智能体对比实验
作者:Ankur Goyal, Andrew Qu
原文:查看原文
本文来源:Vercel 官方博客作者:Ankur Goyal(Braintrust 创始人兼 CEO)、Andrew Qu(Vercel 软件负责人)
AI 社区里有一个越来越流行的判断:文件系统和 Bash 可能是 AI 智能体最合适的抽象层。这个思路并不难理解——大语言模型在代码、终端和文件导航上接触过大量训练数据,所以给智能体一个 Shell,让它自己去查、去跑、去拼上下文,听上去很合理。
看起来文件系统是 AI 的下一个大趋势 :) 每个人都在玩这个。这是因为模型在沙盒环境中的编码任务上接受了大量训练,包括 shell 和文件系统。因此,它们在导航目录、读取文件方面变得非常擅长……
— Arpit Bhayani (@arpit_bhayani)模型确实从以编码为主的训练数据中继承了很强的 Shell 操作熟练度。
即便不是编码场景,这条路径也可能成立。Vercel 之前在使用文件系统和 Bash 构建智能体一文中就展示过:把销售电话、支持工单等结构化数据映射成文件系统后,智能体可以通过 grep 找到相关片段、抽取必要内容,再按需构建上下文。
但还有一个更值得认真回答的问题:文件系统也许很适合探索与检索上下文,那在查询结构化数据时,它是不是依然是最优解?为此,团队构建了一套评估框架来做系统比较。
设置评估实验
实验让智能体去查询一个包含 GitHub issues 和 pull requests 的数据集。这类半结构化数据,很接近真实场景中的客户工单、销售对话或协作记录。
问题复杂度从简单到复杂不等:
- 简单查询:“有多少个开放的 issue 提到了
security?” - 复杂查询:“找出有人先报告 bug,后来又有人提交声称修复该 bug 的 pull request 的 issue。”
一共比较了三种方法:
- SQL 智能体:直接查询包含同样数据的 SQLite 数据库
- Bash 智能体:使用
just-bash在文件系统上浏览并查询 JSON 文件 - 文件系统智能体:只提供基础文件工具(搜索、读取),不开放完整 Shell 权限
所有智能体拿到完全相同的问题,并按照准确率进行评分。
初步结果
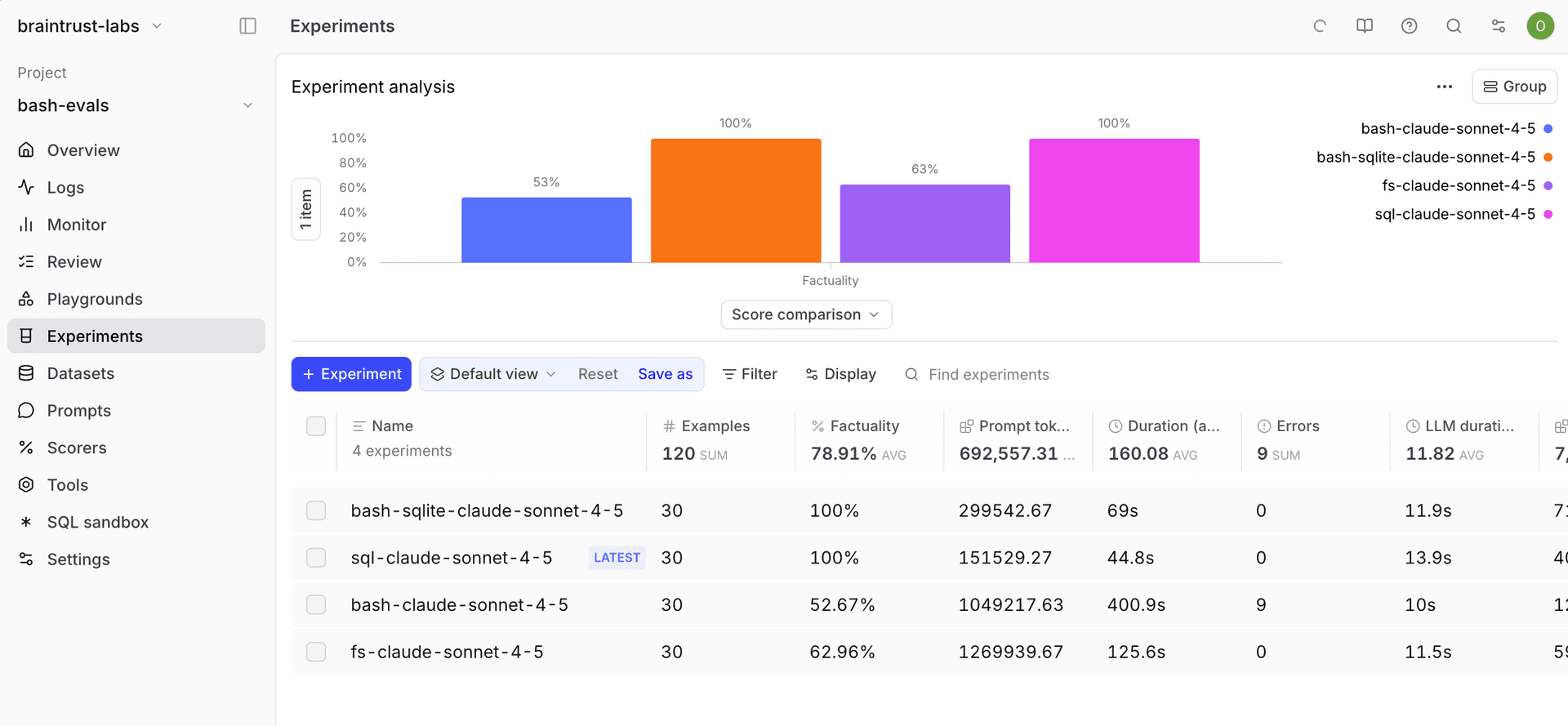
| 智能体 | 准确率 | 平均 Token 数 | 成本 | 耗时 |
|---|---|---|---|---|
| SQL | 100% | 155,531 | $0.51 | 45s |
| Bash | 52.7% | 1,062,031 | $3.34 | 401s |
| 文件系统 | 63.0% | 1,275,871 | $3.89 | 126s |
结果很鲜明:SQL 明显占优。它拿到了 100% 的准确率,而 Bash 只有 52.7%。与此同时,Bash 消耗了约 7 倍的 token,成本高出 6.5 倍,耗时也长了将近 9 倍。即便只是基础文件系统工具,表现也优于完整 Bash 访问,准确率达到了 63%。
你可以直接查看 SQL 实验、Bash 实验和文件系统实验的具体结果。
有一个现象很值得注意:Bash 智能体会生成非常复杂的 Shell 命令,把 find、grep、jq、awk、xargs 组合成非常复杂的流水线。模型显然掌握了不少 Shell 技巧,但这些技巧并没有自动转化成更好的任务结果。
复杂的 Shell 脚本并未转化为更高准确率
调试结果
评估结果也暴露出几个关键问题。
性能瓶颈。 本该在毫秒级完成的命令,在 10 秒后超时。问题最终定位到对 68,000 个文件进行 stat() 调用上。just-bash 后来做了优化来解决这个问题。
缺少 schema 上下文。 Bash 智能体一开始并不知道 JSON 文件的结构。后续在系统提示里补充了 schema 说明与示例命令,确实有帮助,但依然不足以抹平与 SQL 的差距。
评估标准本身也有问题。 团队手工复核失败案例后发现,有几道题的“标准答案”本身就不准确,或者 Bash 智能体找到了额外但同样有效的结果,反而被评分器误判为错误。最终有五道题得到了修正:
- “哪些仓库有最多独立 issue 报告者”这道题在组织维度和仓库维度之间存在歧义
- 几道题的预期输出与真实数据集并不一致
- Bash 智能体有时找到了比参考答案更完整的有效结果
Vercel 团队随后提交了一个修正这些问题的 PR。
在 just-bash 和评估框架都修复之后,方法之间的表现差距缩小了很多。
混合方案
接下来,团队尝试了另一种思路:不要在两种抽象之间二选一,而是把两种能力同时给到智能体。
- 用 Bash 负责探索和操作文件
- 同时在适合的时候提供 SQLite 查询能力
这个混合智能体发展出了一种很有意思的行为:它先运行 SQL 查询,再回到文件系统里用 grep 做交叉验证。也正是这种“先查、再验”的策略,让混合方案能稳定达到 100% 准确率,而不是只靠一次查询就结束。
你可以直接查看混合实验结果。
代价当然也有:混合方案的 token 消耗大约是纯 SQL 的两倍,因为模型需要额外思考工具选择,并对结果进行验证。
关键学习
在修复 just-bash、评估数据集和数据加载问题之后,bash + sqlite 组合成了最可靠的方法。真正的赢家不是某一次跑分里的“原始准确率”,而是能否把自我验证纳入工作流,持续得到稳定结果。
混合方法在准确率上追平 SQL,同时引入了自我验证
在 200 多条消息和数百条追踪之后,团队最终得到这些收获:
- 修复了
just-bash的性能瓶颈 - 更正了评估中五个模糊或错误的预期答案
- 找到了导致结果偏差的数据加载 bug
- 观察到智能体会自然发展出复杂的验证策略
Bash 智能体“习惯复查自己结果”的倾向证明很有价值。它不只是提高准确率,也帮助发现了纯 SQL 路径容易忽略的问题。
这对智能体设计意味着什么
对于 schema 清晰的结构化数据,SQL 依然是最直接、最高效的路径:快、清晰,而且更省 token。
但在探索与验证环节,Bash 仍然很有价值。它让智能体可以检查文件、抽样核对结果,并通过文件系统访问覆盖更多边缘情况。
更大的启发其实在于评估本身。Braintrust 和 Vercel 团队来回迭代、逐条追踪、修正基准,才真正推动了工具和评估框架变好。如果没有这种可见性,大家很容易在一份有缺陷的数据上争论“哪种抽象更强”。
运行你自己的基准测试
你可以把里面的内容替换成自己的真实场景:
- 数据集(客户工单、销售电话、日志,或任何你正在处理的数据)
- 智能体实现方式
- 对你业务真正重要的问题集合
本文由 Ankur Goyal 与 Braintrust 团队撰写,他们专注于为 AI 应用构建评估基础设施。评估框架已开源,并与 Vercel 的 just-bash 集成。