AGENTS.md vs Skills:被动上下文为何胜过主动检索
作者:Vercel Team
原文:查看原文
本文来源:Vercel 官方博客
问题的起源
AI 编程助手依赖的训练数据会过时。Next.js 16 引入了 'use cache'、connection() 和 forbidden() 等新 API,这些都不在当前模型的训练数据中。当智能体不了解这些 API 时,它们会生成错误的代码或回退到旧模式。
反过来也是如此——如果你运行的是旧版本的 Next.js,模型可能会建议你项目中还不存在的新 API。Vercel 团队希望通过让智能体访问版本匹配的文档来解决这个问题。
两种教学方法
在深入结果之前,先快速解释一下测试的两种方法:
Skills(技能)
Skills 是一个开放标准,用于打包编程智能体可以使用的领域知识。一个 Skill 捆绑了提示词、工具和文档,智能体可以按需调用。理念是智能体识别何时需要框架特定的帮助,调用 Skill,然后获得相关文档的访问权限。
AGENTS.md
AGENTS.md 是项目根目录中的一个 Markdown 文件,为编程智能体提供持久上下文。无论你在 AGENTS.md 中放什么,智能体在每一轮都可以访问,无需智能体决定加载它。Claude Code 使用 CLAUDE.md 实现相同的目的。
Vercel 团队构建了一个 Next.js 文档 Skill 和一个 AGENTS.md 文档索引,然后通过评估套件运行它们,看哪个表现更好。
最初押注 Skills
Skills 看起来是正确的抽象。你将框架文档打包成一个 Skill,智能体在处理 Next.js 任务时调用它,然后你得到正确的代码。关注点清晰分离,上下文开销最小,智能体只加载它需要的内容。甚至在 skills.sh 上有一个不断增长的可重用 Skills 目录。
团队期望智能体遇到 Next.js 任务时,调用 Skill,阅读版本匹配的文档,然后生成正确的代码。
然后他们运行了评估测试。
Skills 没有被可靠触发
在 56% 的评估案例中,Skill 从未被调用。智能体可以访问文档但没有使用它。添加 Skill 相比基线没有产生任何改进:
| 配置 | 通过率 | 相比基线 |
|---|---|---|
| 基线(无文档) | 53% | — |
| Skill(默认行为) | 53% | +0pp |
零改进。Skill 存在,智能体可以使用它,但智能体选择不用。在详细的构建/检查/测试分解中,Skill 在某些指标上实际上比基线表现更差(测试 58% vs 63%),这表明环境中未使用的 Skill 可能会引入噪音或干扰。
这不是他们设置的独特问题。智能体不可靠地使用可用工具是当前模型的已知局限。
明确指令有帮助,但措辞很脆弱
团队尝试在 AGENTS.md 中添加明确指令,告诉智能体使用 Skill。
在编写代码之前,首先探索项目结构,然后调用 nextjs-doc skill 获取文档。这将触发率提高到 95% 以上,并将通过率提升到 79%。
| 配置 | 通过率 | 相比基线 |
|---|---|---|
| 基线(无文档) | 53% | — |
| Skill(默认行为) | 53% | +0pp |
| Skill + 明确指令 | 79% | +26pp |
这是一个显著的改进。但他们发现了关于指令措辞如何影响智能体行为的意外情况。
不同的措辞产生了截然不同的结果:
| 指令 | 行为 | 结果 |
|---|---|---|
| "你必须调用 skill" | 先读文档,锚定文档模式 | 错过项目上下文 |
| "先探索项目,然后调用 skill" | 先建立心智模型,将文档作为参考 | 更好的结果 |
相同的 Skill。相同的文档。基于细微措辞变化的不同结果。
在一个评估测试中('use cache' 指令测试),"先调用"方法写出了正确的 page.tsx,但完全错过了所需的 next.config.ts 更改。"先探索"方法两者都做对了。
这种脆弱性令人担忧。如果小的措辞调整会产生大的行为波动,这种方法在生产使用中感觉很脆弱。
构建可信的评估测试
在得出结论之前,他们需要可以信任的评估测试。最初的测试套件有模糊的提示词,验证实现细节而不是可观察行为的测试,以及对已经在模型训练数据中的 API 的关注。他们没有测量真正关心的东西。
团队通过消除测试泄漏、解决矛盾和转向基于行为的断言来强化评估套件。最重要的是,他们添加了针对模型训练数据中不存在的 Next.js 16 API 的测试。
重点评估套件中的 API:
connection()用于动态渲染'use cache'指令cacheLife()和cacheTag()forbidden()和unauthorized()proxy.ts用于 API 代理- 异步
cookies()和headers() after()、updateTag()、refresh()
以下所有结果都来自这个强化的评估套件。每个配置都根据相同的测试进行评判,并进行重试以排除模型差异。
有效的直觉
如果完全消除决策会怎样?与其希望智能体调用 Skill,不如直接在 AGENTS.md 中嵌入文档索引。不是完整的文档,只是一个索引,告诉智能体在哪里找到与项目 Next.js 版本匹配的特定文档文件。然后智能体可以根据需要读取这些文件,无论你使用的是最新版本还是维护旧项目,都能获得版本准确的信息。
团队在注入的内容中添加了一个关键指令:
重要:对于任何 Next.js 任务,优先使用检索引导的推理而不是预训练引导的推理。这告诉智能体查阅文档,而不是依赖可能过时的训练数据。
令人惊讶的结果
团队在所有四种配置上运行了强化的评估套件:
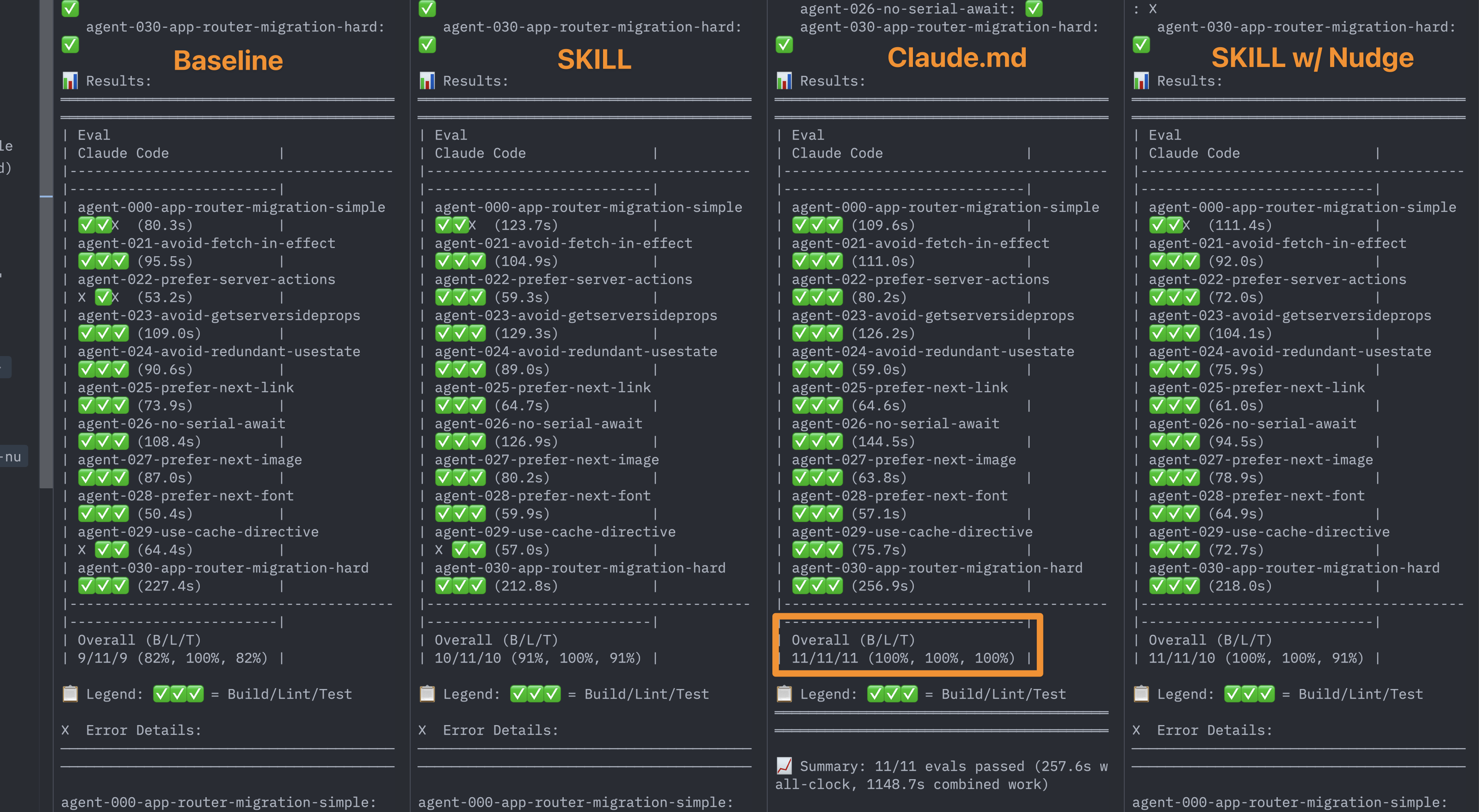
最终通过率:
| 配置 | 通过率 | 相比基线 |
|---|---|---|
| 基线(无文档) | 53% | — |
| Skill(默认行为) | 53% | +0pp |
| Skill + 明确指令 | 79% | +26pp |
| AGENTS.md 文档索引 | 100% | +47pp |
在详细分解中,AGENTS.md 在构建、检查和测试中获得了完美分数。
| 配置 | 构建 | 检查 | 测试 |
|---|---|---|---|
| 基线 | 84% | 95% | 63% |
| Skill(默认行为) | 84% | 89% | 58% |
| Skill + 明确指令 | 95% | 100% | 84% |
| AGENTS.md | 100% | 100% | 100% |
这不是他们预期的。"笨"方法(静态 Markdown 文件)胜过了更复杂的基于 Skill 的检索,即使在他们微调 Skill 触发器时也是如此。
为什么被动上下文胜过主动检索?
团队的工作理论归结为三个因素:
没有决策点。使用
AGENTS.md,不存在智能体必须决定"我应该查这个吗?"的时刻。信息已经存在。一致的可用性。Skills 异步加载,仅在调用时加载。
AGENTS.md内容在每一轮的系统提示词中。没有排序问题。Skills 创建排序决策(先读文档 vs 先探索项目)。被动上下文完全避免了这一点。
解决上下文膨胀问题
在 AGENTS.md 中嵌入文档有上下文窗口膨胀的风险。团队通过压缩解决了这个问题。
最初的文档注入大约 40KB。他们将其压缩到 8KB(减少 80%),同时保持 100% 的通过率。压缩格式使用管道分隔结构,将文档索引打包到最小空间:
[Next.js Docs Index]|root: ./.next-docs|IMPORTANT: Prefer retrieval-led reasoning over pre-training-led reasoning|01-app/01-getting-started:{01-installation.mdx,02-project-structure.mdx,...}|01-app/02-building-your-application/01-routing:{01-defining-routes.mdx,...}完整索引涵盖 Next.js 文档的每个部分:

智能体知道在哪里找到文档,而无需在上下文中包含完整内容。当它需要特定信息时,它从 .next-docs/ 目录读取相关文件。
亲自尝试
一个命令就能为你的 Next.js 项目设置:
npx @next/codemod@canary agents-md此功能是官方 [@next/codemod 包](https://github.com/vercel/next.js/pull/88961?的一部分。
这个命令做三件事:
- 检测你的 Next.js 版本
- 下载匹配的文档到
.next-docs/ - 将压缩索引注入到你的
AGENTS.md
如果你使用的是尊重 AGENTS.md 的智能体(如 Cursor 或其他工具),同样的方法也适用。
对框架作者的意义
Skills 并非无用。AGENTS.md 方法为智能体如何在所有任务中使用 Next.js 提供了广泛的横向改进。Skills 更适合用户明确触发的垂直、特定于操作的工作流,如"升级我的 Next.js 版本"、"迁移到 App Router"或应用框架最佳实践。这两种方法相互补充。
也就是说,对于一般的框架知识,被动上下文目前胜过按需检索。如果你维护一个框架并希望编程智能体生成正确的代码,考虑提供一个用户可以添加到项目中的 AGENTS.md 片段。
实用建议:
不要等待 Skills 改进。随着模型在工具使用方面变得更好,差距可能会缩小,但现在结果很重要。
积极压缩。你不需要在上下文中包含完整的文档。指向可检索文件的索引同样有效。
用评估测试。构建针对训练数据中不存在的 API 的评估。这是文档访问最重要的地方。
为检索而设计。构建你的文档,使智能体可以查找和阅读特定文件,而不是需要预先提供所有内容。
目标是将智能体从预训练引导的推理转向检索引导的推理。AGENTS.md 被证明是实现这一目标的最可靠方法。
研究和评估:Jude GaoCLI 可用:npx @next/codemod@canary agents-md
关键要点
被动上下文 > 主动检索:在当前模型能力下,始终可用的上下文比按需调用的 Skills 更可靠
压缩是关键:8KB 的压缩索引就足够达到 100% 通过率,不需要完整文档
消除决策点:不让智能体决定"是否需要查文档",而是让文档始终可用
版本匹配很重要:确保智能体访问的文档与项目实际使用的框架版本匹配
两种方法互补:AGENTS.md 适合横向的框架知识,Skills 适合垂直的特定工作流
对 Vibe Coder 的启示
这个研究对我们使用 AI 编程助手有重要启示:
- 优先使用 CLAUDE.md/AGENTS.md:将关键的框架知识、项目约定、架构决策直接写入配置文件
- 保持配置文件精简:使用压缩的索引格式,指向详细文档的位置,而不是把所有内容都塞进去
- Skills 用于特定任务:将 Skills 保留给明确的、可触发的工作流,如代码迁移、升级等
- 测试驱动优化:构建评估测试来验证你的配置是否真正提升了 AI 的表现
记住**:上下文是王道**,但如何提供上下文同样重要。被动、持久的上下文目前比主动、按需的检索更有效。